

(1) Feng Liang, The University of Texas at Austin and Work partially done during an internship at Meta GenAI (Email: [email protected]);
(2) Bichen Wu, Meta GenAI and Corresponding author;
(3) Jialiang Wang, Meta GenAI;
(4) Licheng Yu, Meta GenAI;
(5) Kunpeng Li, Meta GenAI;
(6) Yinan Zhao, Meta GenAI;
(7) Ishan Misra, Meta GenAI;
(8) Jia-Bin Huang, Meta GenAI;
(9) Peizhao Zhang, Meta GenAI (Email: [email protected]);
(10) Peter Vajda, Meta GenAI (Email: [email protected]);
(11) Diana Marculescu, The University of Texas at Austin (Email: [email protected]).
Table of Links
- Abstract and Introduction
- 2. Related Work
- 3. Preliminary
- 4. FlowVid
- 4.1. Inflating image U-Net to accommodate video
- 4.2. Training with joint spatial-temporal conditions
- 4.3. Generation: edit the first frame then propagate
-
- Experiments
- 5.1. Settings
- 5.2. Qualitative results
- 5.3. Quantitative results
- 5.4. Ablation study and 5.5. Limitations
- Conclusion, Acknowledgments and References
- A. Webpage Demo and B. Quantitative comparisons
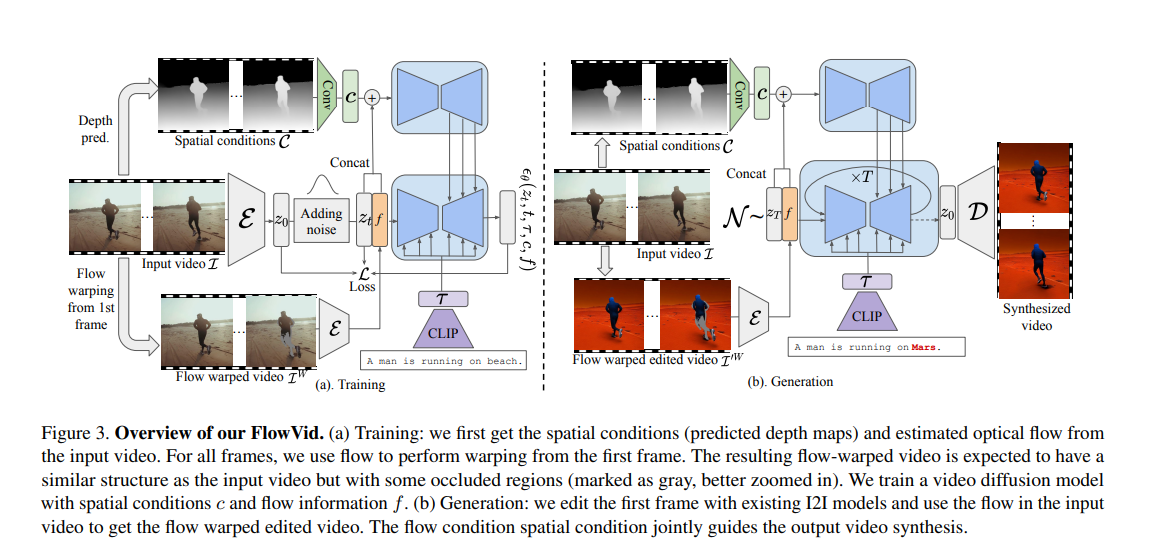
4. FlowVid
For video-to-video generation, given an input video with N frames I = {I1, . . . , IN } and a text prompt τ , the goal is transfer it to a new video I ′ = {I ′ 1 , . . . , I′ N } which adheres to the provided prompt τ ′ , while keeping consistency across frame. We first discuss how we inflate the image-to-image diffusion model, such as ControlNet to video, with spatialtemporal attention [6, 25, 35, 46] (Section 4.1) Then, we introduce how to incorporate imperfect optical flow as a condition into our model (Section 4.2). Lastly, we introduce the edit-propagate design for generation (Section 4.3).
This paper is available on arxiv under CC 4.0 license.