

(1) Feng Liang, The University of Texas at Austin and Work partially done during an internship at Meta GenAI (Email: [email protected]);
(2) Bichen Wu, Meta GenAI and Corresponding author;
(3) Jialiang Wang, Meta GenAI;
(4) Licheng Yu, Meta GenAI;
(5) Kunpeng Li, Meta GenAI;
(6) Yinan Zhao, Meta GenAI;
(7) Ishan Misra, Meta GenAI;
(8) Jia-Bin Huang, Meta GenAI;
(9) Peizhao Zhang, Meta GenAI (Email: [email protected]);
(10) Peter Vajda, Meta GenAI (Email: [email protected]);
(11) Diana Marculescu, The University of Texas at Austin (Email: [email protected]).
Table of Links
- Abstract and Introduction
- 2. Related Work
- 3. Preliminary
- 4. FlowVid
- 4.1. Inflating image U-Net to accommodate video
- 4.2. Training with joint spatial-temporal conditions
- 4.3. Generation: edit the first frame then propagate
-
- Experiments
- 5.1. Settings
- 5.2. Qualitative results
- 5.3. Quantitative results
- 5.4. Ablation study and 5.5. Limitations
- Conclusion, Acknowledgments and References
- A. Webpage Demo and B. Quantitative comparisons
A. Webpage Demo
We highly recommend looking at our demo web by opening the https://jeff-liangf.github.io/ projects/flowvid/ to check the video results.
B. Quantitative comparisons
B.1. CLIP scores
Inspired by previous research, we utilize CLIP [36] to evaluate the generated videos’ quality. Specifically, we measure 1) Temporal Consistency (abbreviated as Tem-Con), which is the mean cosine similarity across all sequential frame pairs, and 2) Prompt Alignment (abbreviated as Pro-Ali), which calculates the mean cosine similarity between a given text prompt and all frames in a video. Our evaluation, detailed in Table 2, includes an analysis of 116 video-prompt pairs from the DAVIS dataset. Notably, CoDeF [32] and Rerender [49] exhibit lower scores in both temporal consistency and prompt alignment, aligning with the findings from our user study. Interestingly, TokenFlow shows superior performance in maintaining temporal consistency. However, it is important to note that TokenFlow occasionally underperforms in modifying the video, leading to outputs that closely resemble the original input. Our approach not only secures the highest ranking in prompt alignment but also performs commendably in temporal consistency, achieving second place.
B.2. Runtime breakdown
We benchmark the runtime with a 512 × 512 resolution video containing 120 frames (4 seconds video with FPS of 30). Our runtime evaluation was conducted on a 512 × 512 resolution video comprising 120 frames, equating to a 4-second clip at 30 frames per second (FPS). Both our methods, FlowVid, and Rerender [49], initially create key frames
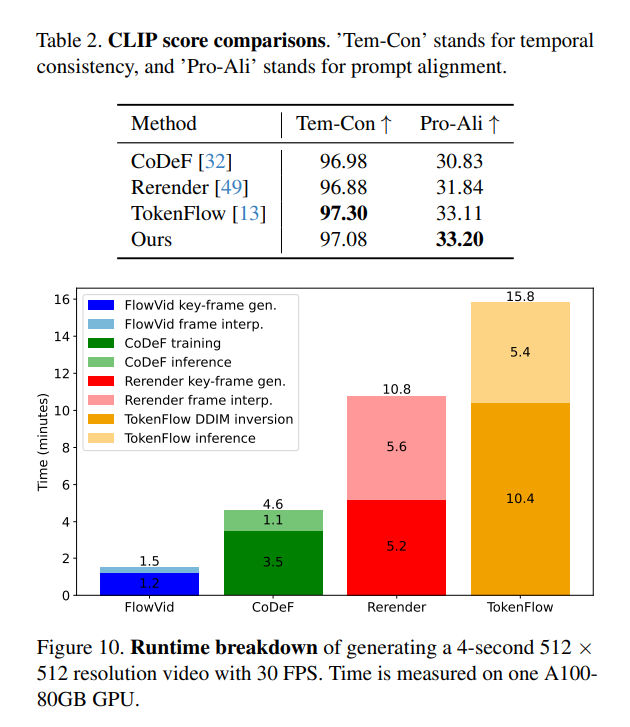
followed by the interpolation of non-key frames. For these techniques, we opted for a keyframe interval of 4. FlowVid demonstrates a marked efficiency in keyframe generation, completing 31 keyframes in just 1.1 minutes, compared to Rerender’s 5.2 minutes. This significant time disparity is attributed to our batch processing approach in FlowVid, which handles 16 images simultaneously, unlike Rerender’s sequential, single-image processing method. In the aspect of frame interpolation, Rerender employs a reference-based EbSynth method, which relies on input video’s non-key frames for interpolation guidance. This process is notably timeconsuming, requiring 5.6 minutes to interpolate 90 non-key frames. In contrast, our method utilizes a non-referencebased approach, RIFE [21], which significantly accelerates the process. Two other methods are CoDeF [32] and TokenFlow [13], both of which necessitate per-video preparation. Specifically, CoDeF involves training a model for reconstructing the canonical image, while TokenFlow requires a 500-step DDIM inversion process to acquire the latent representation. CoDeF and TokenFlow require approximately 3.5 minutes and 10.4 minutes, respectively, for this initial preparation phase.
This paper is available on arxiv under CC 4.0 license.