

Authors:
(1) Xueying Mao, School of Computer Science, Fudan University, China (xymao22@[email protected]);
(2) Xiaoxiao Hu, School of Computer Science, Fudan University, China ([email protected]);
(3) Wanli Peng, School of Computer Science, Fudan University, China ([email protected]);
(4) Zhenliang Gan, School of Computer Science, Fudan University, China (zlgan23@[email protected]);
(5) Qichao Ying, School of Computer Science, Fudan University, China ([email protected]);
(6) Zhenxing Qian, School of Computer Science, Fudan University, China and a Corresponding Author ([email protected]);
(7) Sheng Li, School of Computer Science, Fudan University, China ([email protected]);
(8) Xinpeng Zhang, School of Computer Science, Fudan University, China ([email protected]).
Editor's note: This is Part 6 of 7 of a study describing the development of a new method to hide secret messages in semantic features of videos, making it more secure and resistant to distortion during online sharing. Read the rest below.
Table of Links
- Abstract and 1. Introduction
- 2. Related Work
- 3. Proposed Approach
-
- Experiments
- 4.1. Experimental Setups
- 4.2. Performance Analysis
- 4.3. Ablation Study
- Conclusions and References
4.3. Ablation Study
Embedding Position of Secret Message. In our generation network with 9 Secret-ID blocks, we explore different positions for embedding the secret message. We divide the secret message into two 9-bit segments and allocate their positions. In detail, Setting (a): 1st-4th blocks and 5th-9th blocks.
Setting (b): 1st-2nd blocks and 3rd-4th blocks. Setting (c): 5th-6th blocks and 7th-8th blocks. They are in comparison of the standard setting of RoGVS: 1st-3rd blocks and 4th-6th blocks.
Table 2 displays the performance for these four setups. Both Settings b and c show a considerable decrease compared to Settings a and d, suggesting that adding more Secret-ID blocks improves performance. Notably, Setting c outperforms Setting b, indicating the higher influence of subsequent blocks on the generated image.
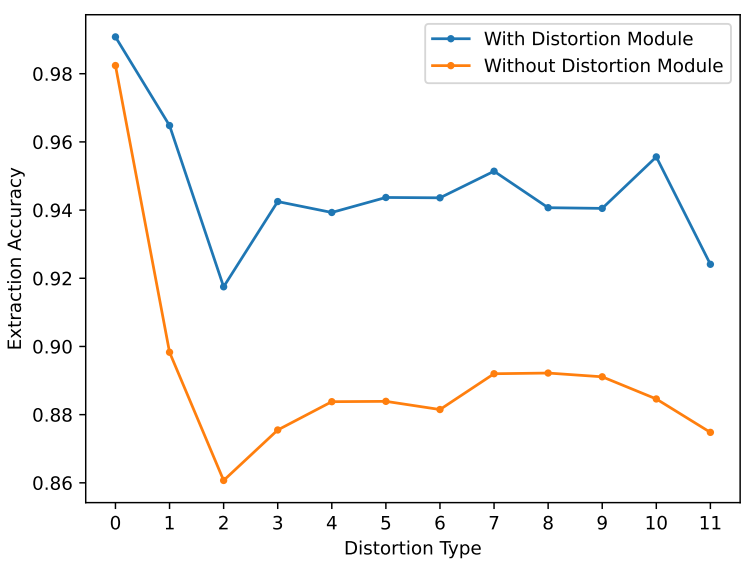
Ablation on Attacking Layer, λ & Discriminator. Fig 5 shows even without the module, our method demonstrates considerable robustness, surpassing the three comparative methods. The addition of attacking layer improves accuracy by an average of 6%. Table 3 presents the impact of λ on the extraction accuracy. More ablation results on λ and the discriminator are displayed in the supplement.
This paper is available on arxiv under CC 4.0 license.